교육 및 대외활동
[삼성 SDS Brightics] 신용카드 승인 예측(Credit Card Approval Prediction)
- -
728x90
📚 신용카드 승인 예측(Credit Card Approval Prediction)
📌 프로젝트 개요
| 수행 기간 | 2022.07 |
| 사용 데이터 | Kaggle 오픈 데이터 |
| 사용 프로그램 및 언어 | Brightics Studio, Python |
📌 주제 선정 배경
- 다루어보지 못했던 주제의 데이터를 활용한다.
- 공공 데이터로 구현할 수 있어야한다.
- 브라이틱스 스튜디오로 해보는 첫 분석이니 많이 구현해본 이진분류_예측 모델을 만들어보자.
이 세 가지를 고려해 데이터를 찾아보았으며,
Kaggle의 Credit Card Approval Prediction (kaggle.com) 데이터를 활용하기로 결정했다.
Credit Card Approval Prediction
A Credit Card Dataset for Machine Learning
www.kaggle.com
📌 주제
'Application의 고객의 사회적·경제적 개인 정보'와 'Credit의 기존 고객 정보'를 사용해
고객들이 신용카드 발급 승인을 받을 수 있을지에 대해 예측한다.
📑 프로젝트 보고서
1. 데이터 소개
- application_record.csv : 예측에 사용할 고객의 사회적/경제적인 개인 정보를 제공

|
ID
|
고객 번호
|
NAME_HOUSING_TYPE
|
거주 유형
|
|
CODE_GEND
|
성별
|
DAYS_BIRTH
|
생일 카운트. 현재(0), -1은 어제를 의미
|
|
FLAG_OWN_CAR
|
차 유무
|
DAYS_EMPLOYED
|
채용 시작일. 현재(0), 양수면 실직자.
|
|
FLAG_OWN_REALTY
|
부동산(자가) 유무
|
FLAG_MOBIL
|
휴대폰 유무
|
|
CNT_CHILDREN
|
자녀 수
|
FLAG_WORK_PHONE
|
업무용 전화 유무
|
|
AMT_INCENT_TOTAL
|
연간 수입
|
FLAG_PHONE
|
전화 유무
|
|
NAME_INBENT_TYPE
|
소득구분
|
FLAG_EMAIL
|
이메일 유무
|
|
NAME_EDUCATION_TYPE
|
교육 수준
|
OCCUPATION_TYPE
|
직업 유형
|
|
NAME_FAMILY_STATUS
|
결혼 여부
|
CNT_FAM_MEMBERS
|
가족 수
|
- credit_record.csv : 기존 고객의 납부 상태, 계약 진행 기간을 제공
|
ID
|
고객 번호
|
|
MONTHS_BALANCE
|
Record month,
0은 현재 월, -1은 이전 월
|
|
STATUS
|
C: 해당 월에 납부완료
X: 해당 월에 대한 대출 없음
0: 연체 1-29일 경과
1:30-59일 경과
2:60-89일 경과
3:90-119일 경과
4:120-149일 경과
5: 연체 150일 이상 경과
|
2. application 데이터 분석
2-1) Profile Table&전처리
- Profile Table로 변수 개수, 결측치 개수 등 Detail 확인

2-2) 결측치 처리_missing value
- empty cell을 null값으로 변경하기_ Replace String Variable 사용

- null이 포함된 행이나 열 지우기_ Delete Missing Data 사용

Before dataframe : 열 18 * 행 438,557
After dataframe : 열 18 * 행 304,354
- 사용할 열 선택하기 _ Select Columns 사용
지우려는 열 = [ CNT_CHILDREN, FLAG_MOBIL]


Before dataframe : 열 18 * 행 304,354
After dataframe : 열 16 * 행 304,354
2-3) 중복값 처리_duplicate value

모델 학습에 ID는 사용하지 않기 때문에 ID를 제외하고,
중복되는 행들은 모두 한번씩만 처리된다는 점을 고려했을 때 중복되는 행은 제거해야겠다고 판단
- 중복되는 행 제거하기 _ Distinct 사용

input columns에 ID를 제외한 모든 컬럼을 넣고 실행한다.
Before dataframe : 열 16 * 행 304,354
After dataframe : 열 16 * 행 62,608
2-4) 이상치 제거_ Outlier
- 이상치 제거하기 _ Outlier Detection 사용
팔레트에는 Outlier Detection 방법이 크게는 두 가지, 작게는 세 가지 옵션으로 나뉘는데,
이를 자세하게 알아보기 위해 세가지로 분류하고, 그 차이에 대해 알아본다.

| Local Outlier Factor | 밀도 기반 이상치 탐색 / 산점도로 이상치 찾음. |
| Tukey | 사분위수 기반 이상치 탐색 IQR=Q3-Q1이고 m이 상수일 때, 이상치 = {x|x>(Q3+m*IQR)} U{x|x<(Q1-m*IQR)} |
| Carling | 사분위수 기반 이상치 탐색 IQR=Q3-Q1이고 m이 상수일 때, 이상치 = {x|x>(median+m*IQR)} U {x|x<(median-m*IQR)} |
먼저 Tukey 방법으로도 실행해보고 LOF로도 실행해봤는데, Tukey에서 제거되는 이상치가 더 많았다.
많은 이상치가 사라지면 분석 결과에 대한 신뢰도 저하의 원인이 되기 때문에 LOF로 진행한다.
더보기
+) 이상치 제거와 관련해서 멘토님께 어떤 방법을 사용해야하는지에 대해 질문을 드렸는데, 멘토님의 답변을 공유하면 좋을 것 같아서 추가로 작성한다.
| 데이터가 정규분포를 따른다(하나의 큰 덩이로 구성) → Tukey/Carling 방식 분포가 여러 개의 그룹으로 나눠져 있고, 어떤 그룹에도 속하지 않는 이상점을 찾고 싶다 → Local Outlier Factor 방식 나뉜 그룹이 각각 정규분포를 따른다면 Group by 연산으로 Tukey/Carling 방식을 적용하는 것도 가능합니다. 또한 어떤 피처들을 입력변수로 선택하느냐에 따라 적절한 알고리즘이 바뀔수도 있으며, 결론적으로는 왕도 없이 데이터의 분포에 맞는 방식을 선택하는 것이 바람직합니다. |

Before dataframe : 열 16 * 행 62,608
After dataframe : 열 16 * 행 57,125
2-5) 명목형 변수 수치화_Label Encoder, One Hot Encoder
- 선택이 binary한 string 변수를 0,1로 라벨링 _ Label Encoder 사용


code_gender_index의 M은 1로, F는 0으로 라벨링 된 것을 확인할 수 있었습니다!
그리고 Select Column에서, 인코딩한 3개의 변수를 제외하고 전체 선택해주었습니다.
- 선택이 multiclass인 string 변수를 one-hot 인코딩(더미 변수로 변환) _ One Hot Encoder 사용


각 string 변수들의 값이 넘버링되어 더미변수로 변환되었음을 확인할 수 있다.
(여기서, Suffix Type을 'Index'로 설정하면 새로 생기는 더미 변수명은
'NAME_INCOME_TYPE_0', 'NAME_INCOME_TYPE_1' 등으로 설정된다.)
모든 문자열을 숫자로 변경한 뒤 Select Column에서, string 변수를 제외하고 전체 선택함.
3. credit 데이터 분석
3-1) Profile Table&전처리
- Profile Table로 변수 개수, 결측치 개수 등 Detail 확인

MONTHS_BALANCE에 0이 많다고 경고했지만, 0이 정수가 아닌 구간의 의미를 가지고 있기 때문에 넘긴다.
STATUS는 예측 종속변수가 될 값으로 신용카드를 승인한다 / 승인하지 않는다 두가지로 분리되어야 한다.
profile table과 맨 첫번째 step, 컬럼명 설명에서 보여주고 있는 것처럼
C,0,X,1,2,3,4,5 총 8가지의 범주로 구분되어있기 때문에,
이 값들을 [C,0,X]=0=승인, [1,2,3,4,5]=1=거부 로 변경한다.

3-2) 이진화_Binarization

- C와 X를 -2,-1인 string으로 변경 _ Replace String Variable 사용
마지막 열에 STATUS_index 열 추가 _ LabelEncoder 사용


- STATUS_index가 2보다 크면 1, 작으면 0을 출력하도록 설정 _ Binarizer 사용

- STATUS와 STATUS_index 열 삭제 + STATUS_BIN의 이름 변경 _ Select Column 사용

4. application 데이터와 credit 데이터 결합
- Application, Credit 데이터를 'ID'를 기준으로 결합 _ Join 사용

application과 credit 데이터를 두 데이터셋에 모두 존재하는 'ID'를 기준으로 병합하려고 한다,
따라서, 'Inner Join'을 사용해야 한다.


Join type은 inner join, left key와 right key는 ID로 설정해주고 두 데이터를 병합한다.
두 데이터가 결합되었음을 output 맨 끝 열 확인으로 확인할 수 있다.
5. 데이터 분할
- Frequency 확인_ Statistic Summary 사용
데이터를 분할하기에 앞서, 결합한 데이터에 대해 종속변수인 STATUS의 빈도수를 파악한다.
왜냐하면 STATUS의 값인 0과 1의 개수의 비율이 비슷하지 않으면,
train, test 데이터 분할과 동시에 over sampling 또는 under sampling을 해야할 수도 있기 때문이다.


STATUS_0:STATUS_1의 비율이 134,530 : 2,444로 상당히 차이가 크다.
두 값의 비율은 98.22 : 1.78로 STATUS의 값이 0에 많이 치우쳐 있고, 이후 sampling이 필요하다는 점도 확인했다.
- 데이터 분할 _ Split 사용

7:3의 비율로 분리하며, Train은 95,881, Test는 41,093 데이터로 분리되었다.
6. 데이터 불균형 처리
|
방법
|
특징
|
|
Under Sampling
(Cluster Centroids)
|
|
|
Over Sampling
(SMOTE)
|
|
|
Random Sampling
|
|
Brightics Studio 1.1 Tutorial
www.brightics.ai
- 라벨이 1인 데이터를 over sampling _Over Sampling(SMOTE) 사용



7. 모델 학습
- 모델 학습 _ Random Forest Classification Train 사용
1) 전체 Columns(All feature) 사용

Feature Columns은 ID와 종속변수인 STATUS를 제외하고 모두 선택한다.
그리고 Label Column은 종속변수인 STATUS를 입력한다.
그럼 오른쪽에 학습 결과에 대한 Report가 출력되는데,
그 중 Feature Importance를 확인한다.

DAYS_EMPLOYED와 DAYS_BIRTH의 importance가 0.1 이상을 보이고 있다는걸 알 수 있다.
즉, 근무 기간과 나이가 신용카드 승인 예측에 가장 영향을 많이 미치고 있다는 뜻이다.
2) 일부 Columns(Part feature) 사용
이번에는 importance가 0.04 이상인 컬럼 9개를 선택한 모델을 학습한 뒤, 전체 컬럼을 대상으로 학습한 모델과 비교한다.
선택할 컬럼 9개는 근무기간, 나이, 연간 수입, 성별, 가족 수, 자가용 유무, 기혼인가?, 전화 유무, 직장인인가? 이다.

근무 기간과 나이 다음으로 importance가 높으면서,
동시에 0.04 이상인 컬럼 9개을 선택해서
Feature Columns에 입력한다.
Label Columns도 STATUS로 입력한다.

결과는 근무기간과 나이의 컬럼의 중요도가 0.2 이상으로 가장 높았고,
연간 수입>가족 수>성별> 자가용 유무/기혼인가?/전화 유무>직장인인가? 순서로 중요도가 높았습니다.
그리고 전체 컬럼 대상 모델과 일부 컬럼 대상 모델을 비교했을 때,
가족 수와 성별에 대한 중요도 우선순위가 바뀌었다는 것을 확인했다.
신용카드가 후납의 특징을 가지고 있는 점과 신용카드 발급 신청 시,
카드사에서는 고객이 결제금액을 납부할 능력이 되는가를 평가하기 위해
고객의 사회적, 경제적 개인정보를 수집한다는 것은 알고 있었다.
하지만, 어떤 요인들이 신용카드 승인에 중요한 영향을 미치는지는 모르고 있었고,
이 단계를 계기로 한 회사에 근무한 기간과 고객의 나이가 신용카드 승인에 큰 영향을 미친다는 것을 알게 되었다.
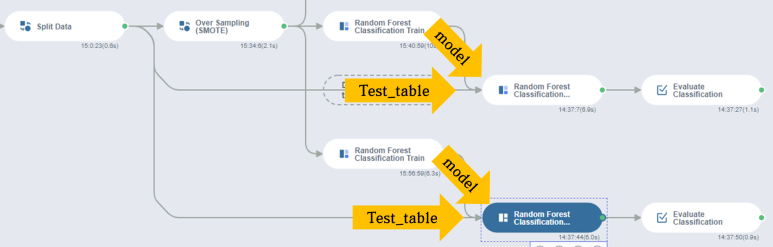
Predict에서는 Train의 'model'과 Split Data의 'test_table'을 받아 모델 예측을 수행한다.
8. 모델 예측
- 모델 예측 _ Random Forest Classification Predict 사용
1) 전체 Columns(All feature) 사용

Inputs에서 table에는 디폴트 값으로 train_table이 입력되어 있는데, 이를 test_table로 변경한다.
Suffix Type는 Label로 설정하고, 실행한다.
결과적으로, output table의 마지막 열에
prediction과 probability가 추가되어있다.


STATUS와 모델의 prediction이 다른 포인트를 산점도로 파악해본다.

붉은 점과 파란 점이 겹치지 않는 포인트가 오류가 발생한 지점인데,
100개의 행 중 3개밖에 오차가 발생하지 않아서 바로 성능평가를 진행한다.
2) 일부 Columns(Part feature) 사용
생략
9. 성능 평가
- 이중분류 모델의 성능평가 지표 :: 혼동행렬
Confusion Matrix(혼동행렬) :
분류모델의 학습 성능을 평가하는 지표로, 실제값과 모델의 예측값을 행렬로 배열한다.
이진분류의 경우, 실제값과 예측값을 비교한 경우를 참과 거짓. T/F로 분류하여 다음과 같은 표로 나타낸다.
|
이진분류(Binary)
|
실제
|
||
|
Positive
|
Negative
|
||
|
예측
|
Positive
|
True Positive (TP)
|
False Positive (FP)
|
|
Negative
|
False Negative (FN)
|
True Negative (TN)
|
|

TP : 실제값 참, 예측값 참
TN : 실제값 거짓, 예측값 거짓
FN : 실제값 참, 예측값 거짓
FP : 실제값 거짓, 예측값 참
- 성능 평가 _ Evaluate Classification 사용

Label Column에는 기존 종속변수 데이터인 STATUS,
Prediction Column에는 모델이 예측한 prediction을
입력해서 실행한다.


두 모델 모두 정확도가 0.94 이상이나 되는 모델이 생성되었다.
전체 컬럼을 이용한 모델에서는 라벨이 0인 데이터에 대해 F1, 정밀도, 재현율 모두 0.95 이상의 점수를 보였고,
중요도가 높은 컬럼을 이용한 모델에서는 라벨이 0인 데이터에 대해 F1, 정밀도, 재현율 모두 0.94 이상의 점수를 보였다.
보완이 필요한 점은, 라벨이 1인 데이터의 점수가 두 모델 모두 낮게 나왔다는 점이다.
기회가 된다면 라벨이 1인 데이터를 대상으로 모델의 성능을 올리는 방법도 공부해보고자 한다.
10. 전체 플로우

320x100
소중한 공감 감사합니다