데이터 분석 프로젝트
[개인 프로젝트] 척추 질환 환자의 특성을 반영한 개인화 서비스 개발로 수익성 향상
- -
728x90
📚 척추 질환 환자의 특성을 반영한 개인화 서비스 개발로 수익성 향상
📌 프로젝트 개요
| 수행 기간 | 2024.02 - 2024.04 |
| 사용 데이터 | 포스코 아카데미 제공 |
| 내용 | 60만건의 환자 진료 데이터를 분석하고, 수술 결과 예측 모델과 재발 예측 모델을 구축함. 또한 이를 활용해 새로운 고객 경험을 제공할 수 있는 프로모션과 서비스를 기획 및 디자인함. |
| 사용 프로그램 및 언어 | Python, Google Colab, Pandas, scikit-learn |
2024.07.23 - [데이터 분석 프로젝트] - [팀 프로젝트] 환자의 특성을 반영한 개인화 서비스 개발로 수익성 향상
[팀 프로젝트] 환자의 특성을 반영한 개인화 서비스 개발로 수익성 향상
📚 환자의 특성을 반영한 개인화 서비스 개발로 수익성 향상 📌 프로젝트 개요 수행 기간2022.10 - 2022.11사용 데이터포스코 아카데미 제공내용60만건의 환자 진단/수술 관련/엑스레이 데이터를
dtdiary.tistory.com
포스코에서 수행했던 빅데이터 프로젝트의 부족한 점을 보완하기 위해 개인적으로 수행하고 보고서를 다시 제작했다.
기존의 분석보다 다양한 변수 기준을 두어 수술 결과와 재발에 영향을 미치는 영향 인자를 파악하고,
이를 활용해 기획할 수 있는 개선안을 제시해 보고서의 질과 양을 풍성히 했다.
또한 기술적인 측면에서도, SMOTE를 사용해 데이터 불균형을 해소하고 XGBoost, LGBM의 모델을 추가 개발해
환자의 특성을 반영해 수술결과와 재발을 예측하는 모델의 정확도를 극대화했다.
아래는 프로젝트에 관한 내용이다.
📑 프로젝트 보고서

1. 추진 배경
2. 현황 및 개선기회


3. 분석 계획

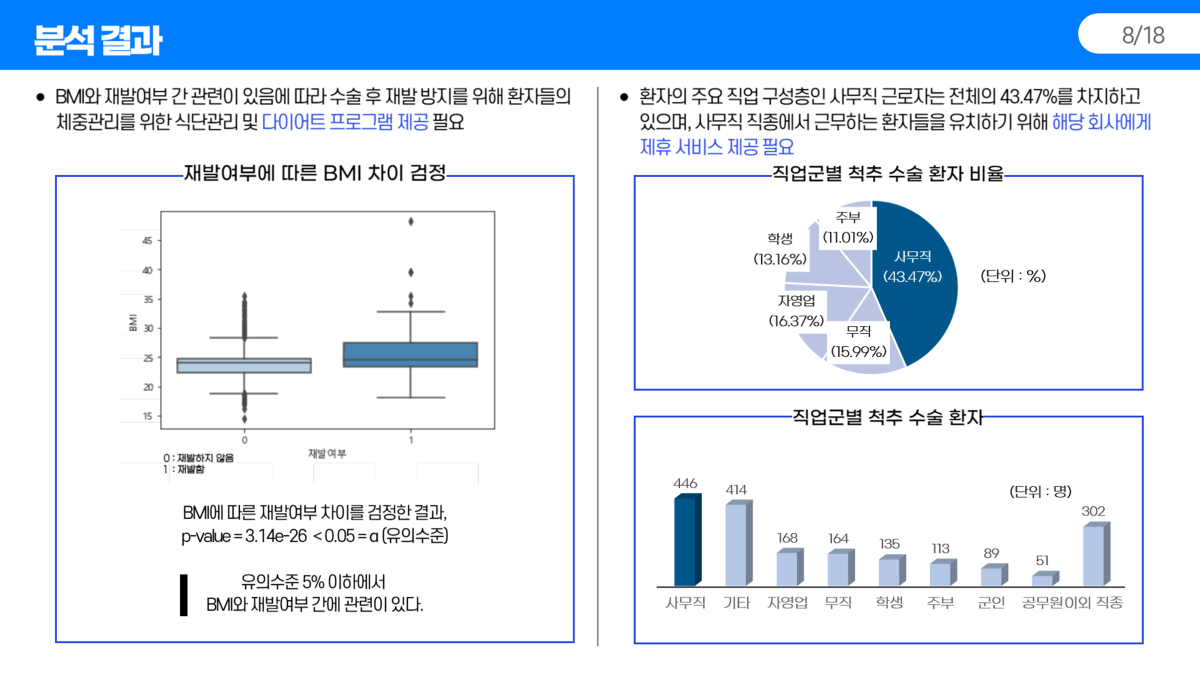
4. 분석 결과



군집분석 코드 보기
더보기
# 군집분석 (수술실패여부)
df_copy = df_raw.copy()
df_copy2 = df_copy.drop(['환자ID', # unique
'ODI','골밀도', # 결측치
'수술시간','수술일자','직업','퇴원일자','입원일자','입원기간','날짜','혈액형', '가족력','수술기법',# 관련없음
'Age','weight','tall','월','요일','계절','신장','체중', # 파생변수
'수술실패여부','재발여부', # 목표변수
'디스크위치','Location of herniation',
'디스크높이차이','LL1','SS' # medical data
],axis=1,inplace=False)
df_copy2 = pd.get_dummies(df_copy2)
df_copy2.info()
from sklearn.cluster import KMeans
from sklearn.metrics.cluster import silhouette_score
scaler = MinMaxScaler()
scaled = scaler.fit_transform(df_copy2)
df_scaled = pd.DataFrame(scaled,columns=df_copy2.columns)
### 클러스터 개수 찾기
ks = range(1,11)
inertias = []
for k in ks :
model = KMeans(n_clusters = k, n_init = 5)
%time model.fit(df_scaled)
inertias.append(model.inertia_)
print('n_cluster : {}, inertia : {}'.format(k, model.inertia_))
plt.figure(figsize = (15, 6))
plt.plot(ks, inertias, '-o')
plt.xlabel('number of clusters, k')
plt.ylabel('inertia')
plt.xticks(ks)
plt.show()
### 클러스터 개수는 4개로 설정
model = KMeans(n_clusters = 4) # 실루엣 계수
k_model = model.fit(df_scaled)
cluster = k_model.labels_
print("Silhouette Score:", silhouette_score(df_scaled, cluster))
### 결과 확인
# yellowbrick 라이브러리의 SilhouetteVisualizer 이용
clus = model
graph_sil = SilhouetteVisualizer(clus, colors='yellowbrick')
#생성된 visualizer에 데이터 입력
graph_sil.fit(df_scaled)
graph_sil.show()
print( "실루엣 계수 = ",format(round(graph_sil.silhouette_score_,3)))
모델링 코드 보기
더보기
df_copy = df_raw.drop(['환자ID','ODI','신장','입원기간','입원일자','직업','체중','퇴원일자','요일','전방디스크높이(mm)',
'후방디스크높이(mm)','골밀도','수술시간','수술일자','혈액형','날짜','tall',
'weight','수술실패여부','Age','디스크위치','월'],axis=1,inplace=False)
df_copy = pd.get_dummies(df_copy)
Y = df_copy.재발여부
X = df_copy.drop("재발여부", axis = 1)
columns = X.columns
scaler = StandardScaler()
X_std = scaler.fit_transform(X)
X_std = pd.DataFrame(X_std, columns = columns)
x_train, x_test, y_train, y_test = train_test_split(X_std, Y, test_size = 0.3, random_state = 1234, stratify=Y)
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=1234)
x_train_over, y_train_over = smote.fit_resample(x_train, y_train)
print("SMOTE 적용 전 학습용 피처/레이블 데이터 세트 : ", x_train.shape, y_train.shape)
print('SMOTE 적용 후 학습용 피처/레이블 데이터 세트 :', x_train_over.shape, y_train_over.shape)
print('SMOTE 적용 후 값의 분포 :\n',pd.Series(y_train_over).value_counts() )
# 로지스틱 회귀 모델
x_train, x_valid, y_train, y_valid = train_test_split(x_train_over, y_train_over, test_size = 0.3, random_state = 1234,stratify = y_train_over)
lr_final = LogisticRegression()
lr_final.fit(x_train, y_train)
y_pred = lr_final.predict(x_valid)
print(classification_report(y_valid,y_pred,digits=3))
y_pred_test = lr_final.predict(x_test)
print(classification_report(y_test,y_pred_test,digits=3))
# 랜덤 포레스트 모델
rf_final = RandomForestClassifier(min_samples_split = 80, min_samples_leaf=40, max_depth = 4, n_estimators = 100, random_state=1234)
rf_final.fit(x_train, y_train)
y_pred = rf_final.predict(x_valid)
print(classification_report(y_valid, y_pred, digits=3))
y_pred_test = rf_final.predict(x_test)
print(classification_report(y_test, y_pred_test, digits=3))
#LGBM
X = df_raw.drop(['환자ID','ODI','신장','입원기간','입원일자','직업','체중','퇴원일자','요일','전방디스크높이(mm)','후방디스크높이(mm)','골밀도',\
'수술시간','수술일자','수술실패여부','재발여부','혈액형','날짜','tall','weight','연령','월'],axis=1,inplace=False)
target = df_raw['재발여부']
feature = pd.get_dummies(X)
train_x, test_x, train_y, test_y = train_test_split(feature,target,test_size=0.3, random_state =1234 ,stratify=target)
train_x_over, train_y_over = smote.fit_resample(train_x, train_y)
## 하이퍼 파라미터 튜닝 :: StratifiedKFold
score = []
def lgbm_optimization(trial):
score = []
skf = StratifiedKFold(n_splits = 4 , random_state = 42 , shuffle = True)
for train_fold, test_fold in tqdm(skf.split(train_x_over, train_y_over), desc = 'k_fold'):
X_train, X_valid, y_train, y_valid = train_x_over.iloc[train_fold], train_x_over.iloc[test_fold], train_y_over.iloc[train_fold], train_y_over.iloc[test_fold]
params = {
"boosting_type" : trial.suggest_categorical('boosting_type',['dart','gbdt']),
"learning_rate": trial.suggest_uniform('learning_rate', 0.2, 0.99),
"n_estimators": trial.suggest_int("n_estimators", 100, 300, step=10),
"max_depth": trial.suggest_int("max_depth", 1, 15),
"num_leaves": trial.suggest_int("num_leaves", 2, 256),
"reg_alpha": trial.suggest_float("reg_alpha", 1e-4, 1),
"reg_lambda": trial.suggest_float("reg_lambda", 1e-4, 1),
"subsample": trial.suggest_float("subsample", 0.4, 1.0),
"subsample_freq": trial.suggest_int("subsample_freq", 1, 30),
"colsample_bytree": trial.suggest_float("colsample_bytree", 0.1, 1.0),
"min_child_samples": trial.suggest_int("min_child_samples", 5, 50),
"max_bin": trial.suggest_int("max_bin", 50, 100),
"verbosity": -1,
"random_state": trial.suggest_int("random_state", 1, 10000)
}
model_lgbm = LGBMClassifier(**params)
model_lgbm.fit(X_train, y_train)
lgbm_cv_pred = model_lgbm.predict(X_valid)
score_cv = f1_score(y_valid, lgbm_cv_pred , average = 'macro')
score.append(score_cv)
print(score)
return np.mean(score)
sampler = TPESampler()
optim = optuna.create_study(
study_name="lgbm_parameter_opt",
direction="maximize",
sampler=sampler,
)
optim.optimize(lgbm_optimization, n_trials=50)
print("Best macro-F1:", optim.best_value)
print("Best params:", optim.best_params)5. 개선안





6. 데이터 파일 및 구현 코드
척추_전체 코드구현.ipynb
7.15MB
Patient_Surgery_Data.csv
0.13MB
Medical_Image_Data_01.csv
0.13MB
Patient_Diagnosis_Data.csv
0.17MB
320x100
소중한 공감 감사합니다